But could large language models reason?
Large language models (LLMs) are masters of linguistic form. This means they can also (often) reproduce the form of basic reasoning problems, such as those in physics, logic or mathematics, especially if they can outsource some of the cognitive load through chain-of-thought prompting. They can even reason with counterfactuals, as long as low-level features of the text provide them with the necessary information. Or at least, they can perform such reasoning tasks at the utterance level. At the deeper, algorithmic level, their information processing remains divorced from the causal structure of the world, leaving them deprived of grounding and, I'd argue, true reasoning capabilities. Could they improve on this?

Ungrounded machines
The debut of GPT4 promised increased reasoning capabilities and that may very well be true. A scaled-up version of OpenAI's previous model should have mastered the linguistic form of reasoning problems even more. The fact that GPT4 accepts multimodal inputs may also increase its capacities (Zhang et al., 2023). Assuming that OpenAI's secrecy is not obscuring deep changes, it is to be expected that GPT4 will be capable of the same types of reasoning, but better. After all, it still has no access to causal relations.
Of course, what it does have are causal statements in the corpus of LLMs and one might intuit that having enough of these can lead to causal understanding. After all, wasn't most our own knowledge about cause and effect in the world also learnt via written or spoken statements? I agree that humans can learn from such statements, but I don't think they are enough for LLMs – something I hope to elaborate on later. For now let's just say that I think we need the ability to map causal statements onto specific interventions in the world (whether real or simulated) for us to be able to reason causally with those statements. This is closely related to the concept of understanding and the symbol grounding problem.
So why does it often seem like LLMs are reasoning about causal structure? The difficult thing here is that their responses are based on a corpus that contains many references to the causal structure of the world. Reproducing these linguistic statements mirrors these references and suggests to us humans – sensitive as we are to linguistic utterances – that the speakers gets these references, too. But although it can be argued that LLMs contain some sort of world model, they remain separated from a world that language refers to.
World models
There is no reason to presume, however, that machine cognition will always be limited this way. For example, let's return to the issue of an LLM trained on the board game Othello. As mentioned in an earlier post, this LLM was argued to not only generate representations of the game board and of legit moves, but also to have used the board representation to determine moves (Li et al., 2022). What is key here is that the LLM was tasked to predict legit game moves and so started representing the structure of the game as it was fed actual moves.
The more common LLM (e.g. GPT4) is tasked to predict words in human-made texts and therefore starts representing a causal structure of such texts. At the risk of repeating it too often, this causal structure of language can reflect the causal structure of the world -- since we talk about the world a lot -- but interpreting it as one and the same thing is a special type of word-referent confusion. It also skips over the notion that the role of language may not be to accurately capture the structure of the world, but rather to influence the behaviour of other humans.
A world (domination) model
The consequence of this is that LLMs trained solely on predicting words for a large corpus have a meta-model of the world at best. Still, it doesn't have to be that way. The LLM could also be trained in conjunction with a program that is causally connected to some world and which gives it feedback. One interesting example of this is Cicero, a program that was taught to play the Realpolitik-simulating board game Diplomacy.
Diplomacy is a brilliant game that combines strategic thinking with social cognition. Players need to consider many different scenarios, estimate likely courses of action of other players and attempt to coordinate them. They are encouraged to seek alliances, make (and sometimes break) promises and to instrumentalize other players. Tactics, strategy and persuasion games provide a recipe for intense negotiation, scenario thinking and paranoia.
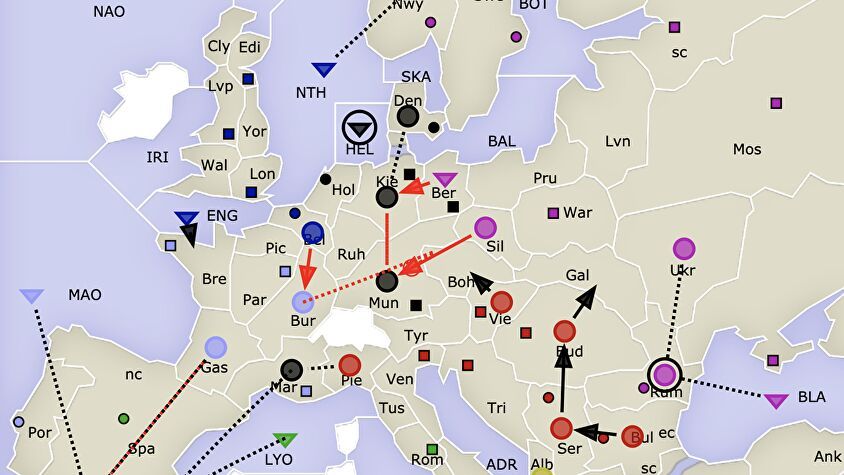
The company Meta managed to build a program that could play this game against humans at a decent level (Meta FAIR et al., 2022). They used an LLM to do so, but not just an LLM. In fact, they engineered a larger system with many specialized modules, some of which required hard coding (e.g. to narrow the type of responses generated by Cicero's LLM or to explicitly map linguistic descriptions onto game actions) and others which required training (e.g. modules dependent on a database of 125k games). A blacklist of invalid messages was added to filter inappropriate responses and reinforcement learning by human feedback (RLHF) took place through annotations by expert players.
With all these nuts and bolts in place, Cicero can strategize and instrumentalize human players, as long as not too much time is allotted to negotiating with them. It makes decisions on the basis of representations of game states and the rules that lead from one state to another – which is arguably causal reasoning at its core. So Cicero is an example of an LLM that, augmented by wholly different modules, appears to reason causally about a piece of the world.
Yet this piece is small - it is only in the domain of playing Diplomacy that Cicero can perform and none of its skills there generalize to other domains. Large parts of its structure, including the correspondence between linguistic statements and game actions, were hard-coded. Even changing the rules of Diplomacy by just a bit would cause Cicero to fail, until it is retrained on (and possibly re-engineered for) a large corpus of games with the new rules. This does not make Cicero any less impressive, though, and the overall design can perhaps be transplanted onto other domains, such as diagnostic reasoning in medicine. It would take renewed engineering, but Cicero could be adapted to reason about different, narrowly defined problem sets.
Critics might claim that this is still a very impoverished version of reasoning. First, at the utterance level, Cicero falls short of providing explanations or justifications of its decision-making process, also known as the reasons of reasoning. Secondly, at the algorithmic level, using pre-programmed causal structures to decide on novel situations is impressive in the face of the complexity of Diplomacy, but we should not oversell it. If a thermostat is not reasoning about temperature and heating, then neither is Cicero doing it about Diplomacy. Instead, it was the engineers who reasoned about relevant causal structures and placed them in Cicero, as if they were the writers of the manual in the Chinese room!
I will admit I am on the fence about the second criticism – the neurobiological basis of human reasoning might be equally mechanistic as a thermostat, after all – but I can see how the engineering contributions muddle the picture and why we should be careful not to use grandiose cognitive vocabulary to describe an inflexible agent.
Python on the fly
The criticism that Cicero cannot provide reasons, however, may be overcome by designing the system in such a way that it can report on its decision-making process. An interesting recent example of a system that can do this is ViperGPT, an LLM-coupled program that draws inferences from images and prompts (Suris et al., 2023). For example, you can show ViperGPT a picture of a number of fruits and two children and ask it how you could fairly distribute the fruits among the children.
Like Cicero, ViperGPT was carefully engineered. It contains an LLM and a computer vision API and if it is presented with an image and a prompt that asks it something about the image, the LLM writes its own Python script on the fly, calling the API to do task-relevant analysis. The script also adds any necessary processing steps. For the example above, it would write a script that calls the API to identify children and fruits in the picture and then performs basic arithmetic on the API output.
As you may imagine, the computer vision program behind the API is doing much of the heavy lifting when analysing pictures. In this sense, much of the cognitive load of a specific task (detecting objects, deciding how they are positioned with respect to each other) may still be comparable to a Chinese room manual. The role of the LLM-written Python code is key, though – it offers a transparent description of the machine's reasoning process. This is reminiscent of the relation that our own verbal reports have to our perceptual apparatus – most of the complicated inferential processing that is involved in visual perception is not consciously accessible to us, but we can still explain how we count objects or estimate whether they'd fit in a box that we see. ViperGPT is therefore an example of explainable AI, machines that meet the justification requirement of reasoning at the utterance level.
The other interesting thing about ViperGPT is that it, in contrast to Cicero, is not built for a narrow domain. The advanced tools of the computer vision API and the general-purpose language generation offered by the LLM make ViperGPT flexible when drawing inferences about images and video.
So, could LLMs reason?
LLMs can mimic the linguistic expression of a reasoning process, if that expression can be built through mastery of linguistic form alone. In that way, LLMs are doing the motions of reasoning and with that they might in time meet the performance metrics that we would use for humans. Yet even if successful on such a metric, this would refer to their capabilities at the utterance level.
One level deeper, LLMs do not show hallmark features of reasoning, but they can be integrated into a larger system that gets closer to reasoning capabilities. These systems, however, are either hard-coded, narrow-domain machines such as Cicero or they lean onto rigid albeit advanced toolkits, like ViperGPT does. In the case of Cicero, the LLM is told how to ground specific language onto game mechanics, while in the case of ViperGPT, the LLM is augmented by a sensory apparatus that helps it to turn imagery into propositional representations. While neither are convincing as reasoning machines, they do suggest that the shape of things to come is modular design featuring both domain-specific and general-purpose units, with LLMs playing a possible role as general-purpose utterance generators.
References
Li, K., Hopkins, A. K., Bau, D., Viégas, F., Pfister, H., & Wattenberg, M. (2022). Emergent world representations: Exploring a sequence model trained on a synthetic task. arXiv preprint arXiv:2210.13382.
Meta Fundamental AI Research Diplomacy Team (FAIR)†, Bakhtin, A., Brown, N., Dinan, E., Farina, G., Flaherty, C., ... & Zijlstra, M. (2022). Human-level play in the game of Diplomacy by combining language models with strategic reasoning. Science, 378(6624), 1067-1074.
Surís, D., Menon, S., & Vondrick, C. (2023). Vipergpt: Visual inference via python execution for reasoning. arXiv preprint arXiv:2303.08128.
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., & Smola, A. (2023). Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923.
Member discussion